指令管線化...
哈佛架構修正哈佛架構Modified Harvard architecture冯·诺伊曼结构資料流架構Dataflow architectureCPU架構比較Comparison of CPU architectures1位元4位元8位元12位元16位元18位元18-bit24位元24-bit31位元31-bit32位元36位元36-bit48位元48-bit64位元128位元256位元256-bit變動位元數位訊號處理器單片機系统芯片并行向量處理機高级电源管理高级配置与电源接口動態時脈調整动态电压调节时钟门控
Instruction processing
計算機數位電子裝置指令處理器時脈邏輯閘正反器正反器邏輯閘正反器RISC時脈週期程序員編譯者組合代碼彙編碼轉發延遲IntelPentium 4 PrescottXeleratorX10q[1]分支預測超級電腦gcov覆蓋率檢查預讀輸入隊列指令快取自我變更的程式中央處理器記憶體管線暫存器Atmel AVRPIC微控制器組合語言冒險

RISC機器的五層管線示意圖(IF:讀取指令,ID:指令解碼,EX:執行,MEM:記憶體存取,WB:寫回暫存器)
指令管線化(英语:Instruction pipeline)是為了讓計算機和其它數位電子裝置能夠加速指令的通過速度(單位時間內被執行的指令數量)而設計的技術。
管線在處理器的內部被組織成層級,各個層級的管線能半獨立地單獨運作。每一個層級都被管理並且鏈接到一條“鏈”,因而每個層級的輸出被送到其它層級直至任務完成。 處理器的這種組織方式能使總體的處理時間顯著縮短。
未管線化的架構產生的效率低,因為有些CPU的模組在其他模組執行時是閒置的。管線化雖並不會完全消除CPU的閒置時間,但是能夠讓這些模組並行運作而大幅提升程式執行的效率。
但並不是所有的指令都是獨立的。在一條簡單的管線中,完成一個指令可能需要5層。如右圖所示,要在最佳性能下運算,當第一個指令被執行時,這個管線需要運行隨後4條獨立的指令。如果隨後4條指令依賴於第一條指令的輸出,管線控制邏輯必須插入延遲時脈周期到管線內,直到依賴被解除。而轉發技術能顯著減少延時。憑藉多個層,雖然管線化在理論上能提高效能,優勝於無管線的內核(假設時脈也因應層的數量按比例增加),但事實上,許多指令碼設計中並不會考慮到理想的執行。
目录
1 簡介
2 優缺點
2.1 優點
2.2 缺點
3 示例
3.1 一般的管線
3.1.1 汽泡
4 複雜化
5 範例
5.1 範例一
5.2 範例二
6 參見
7 外部連結
簡介

RISC機器的五層管線示意圖
管線化是假設程式執行時有一連串的指令要被執行(垂直座標i是指令集,水平座標表時間t)。絕大多數當代的CPU都是利用時脈驅動。
而CPU是由內部的邏輯閘與正反器組成。當受到時脈觸發時,正反器得到新的數值,並且邏輯閘需要一段時間來解析出新的數值,而當受到下一個時脈觸發時正反器又得到新的數值,以此類推。而藉由邏輯閘分散成很多小區塊,再讓正反器鏈接這些小區塊組,使邏輯閘輸出正確數值的時間延遲得以減少,這樣一來就可以減少指令執行所需要的周期。
舉例來說,典型的RISC管線被分解成五個階段,每個階段之間使用正反器鏈接。
- 讀取指令
- 指令解碼與讀取暫存器
- 執行
- 記憶體存取
- 寫回暫存器
優缺點
並非在所有情況下管線技術都起作用。可能有一些缺點。如果一條指令管線能夠在每一個時脈週期接納一條新的指令,被稱為完整管線化(fully pipelined)。因管線中的指令需要延遲處理而要等待數個時脈週期,被稱為非完整管線化。
當一名程序員(或者組合者/編譯者)編寫組合代碼(或者彙編碼)時,他們會假定每個指令是循序執行的。而這個假設會使管線化無效。當此現象發生後程式會表現的不正常,而此現象就是危害。不過目前有提供幾種技術來解決這些危害像是轉發與延遲等。
優點
- 减少了处理器执行指令所需要的時脈週期,在通常情況下增加了指令的輸入頻率(issue-rate)。
- 一些集成電路(combinational circuits),例如加法器(adders)或者乘法器(multipliers),通過添加更多的環路(circuitry)使其工作得更快。如果以管線化替代,能相對地減少環路。
缺點
- 非管線化的處理器每次(at a time)只執行一個指令。防止分支延時(事實上,每個分支都會產生延時)和串行指令被并行執行產生的問題。設計比較簡單和較低生產成本。
- 在執行相同的指令時,非管線化處理器的指令傳輸延遲時間(The instruction latency)比管線化處理器明顯較短。這是因為管線化的處理器必須在數據路徑(data path)中添加額外正反器(flip-flops)。
- 非管線化處理器有固定指令位寬(a stable instruction bandwidth)。管線化處理器的性能更難以預測,並且不同的程序之間的變化(vary)可能更大。
示例
一般的管線

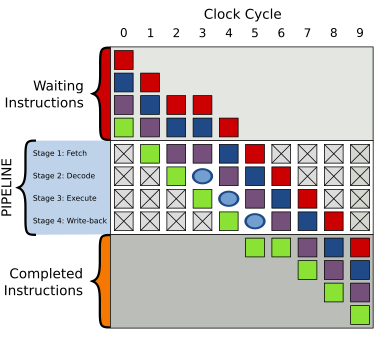
一般的四層管線架構;不同的顏色格表示不同的指令
右圖是一般有4層管線的示意圖:
- 讀取指令(Fetch)
- 指令解碼(Decode)
- 執行指令(Execute)
- 寫回執行结果(Write-back)
上方的大灰色格是一連串未執行的指令;下方的大灰色格則是已執行完成的指令;中間的大白色格則是管線。
執行順序如以下列表所示:
| 時序 | 執行情況 |
|---|---|
| 0 | 四條指令等待執行 |
| 1 |
|
| 2 |
|
| 3 |
|
| 4 |
|
| 5 |
|
| 6 |
|
| 7 |
|
| 8 |
|
| 9 | 所有指令皆執行完畢 |
汽泡
一個氣泡在編號為3的時脈週期中,指令執行被延遲
指令執行中產生一個“打嗝”(hiccup),在管線中生成一個沒有實效的氣泡。
如右圖,在編號為2的時脈週期中,紫色指令的讀取被延遲,並且在編號為3的時脈週期中解碼層也產生了一個氣泡。所有在紫色指令之後的指令都被延遲執行,而在其之前已經執行了的指令則不受影響。
由於氣泡使指令執行延遲了一個時脈週期,完成全部4條指令的執行共需要8個時脈週期。
而氣泡處對指令的讀取、解碼、執行與寫回都沒有實質影響。這可以使用nop代碼來完成。
複雜化
很多處理器的管線深度到5層、7層、10層,甚至31層(像是Intel Pentium 4 Prescott)。Xelerator X10q甚至有多于1000層的管線深度[1]。
| 微架構 (Microarchitecture) | 管線層數 (Pipeline stages) |
|---|---|
| Sony Cell | 23 |
| IBM PowerPC 7 | 17 |
| IBM Xenon | 19 |
| AMD Athlon | 10 |
| AMD Athlon XP | 11 |
| AMD Athlon 64 | 12 |
| AMD Phenom | 12 |
| AMD Opteron | 15 |
| ARM7TDMI (-S) | 3 |
| ARM7EJ-S | 5 |
| ARM810 | 5 |
| ARM9TDMI | 5 |
| ARM1020E | 6 |
| XScale PXA210/PXA250 | 7 |
| ARM1136J (F)-S | 8 |
| ARM1156T2 (F)-S | 9 |
| ARM Cortex-A5 | 8 |
| ARM Cortex-A8 | 13 |
| AVR32 AP7 | 7 |
| AVR32 UC3 | 3 |
DLX | 5 |
Intel P5(Pentium) | 5 |
Intel P6(Pentium Pro) | 14 |
| Intel P6(Pentium III) | 10 |
Intel NetBurst(Willamette) | 20 |
| Intel NetBurst(Northwood) | 20 |
| Intel NetBurst(Prescott) | 31 |
| Intel NetBurst(Cedar Mill) | 31 |
Intel Core | 14 |
Intel Atom | 16 |
| LatticeMico32 | 6 |
| R4000 | 8 |
| StrongARM SA-110 | 5 |
| SuperH SH2 | 5 |
| SuperH SH2A | 5 |
| SuperH SH4 | 5 |
| SuperH SH4A | 7 |
UltraSPARC | 9 |
UltraSPARC T1 | 6 |
UltraSPARC T2 | 8 |
WinChip | 4 |
LC2200 32 bit | 5 |
當程式出現分支將不利於過深管線,整條管線將會無效化。為了減輕此狀況,分支預測就變的重要。如果分支預測錯誤,也能夠藉由自行結束預測來避免加速惡化效率。在某些運用上,像是超級電腦運算,為了能夠將超長管線的運算優勢凸顯出來,會特地將程式寫的極少分支化來避免預測失敗,而且深度的管線化主要是為了能降低每個時脈執行的指令量而設計。當程式經常出現分支,把分支重新排序(像是將更為需要的指令提早放入管線中)而將明顯的降低損失的速度以避免將分支“沖垮”。像是gcov程式能夠使用一種覆蓋率檢查的技術檢查特定分支的執行頻率,但是這種檢查法經常是最佳化的最後手段。處理能力高的管線會因為很多分支的程式而降低效率,這是因為處理器不知道下一個要讀取的指令是甚麼,而需要等待完成分支指令而讓管線清空。處理完分支之後,下一個指令就要經過所有管線,直到整個指令集的結果出現,而處理器才會再繼續執行。而在極端的狀況下,管線化處理器的效能理論上可能會與未管線化處理器一致,甚至是每層管線都在待命狀態,而且指令經常在管線之中跑來跑去時的效能比較差一些。
由於指令管線化,處理器讀取機器碼時並不會立即執行。因為如此,在很接近的地方執行更新機器碼的動作就可能無法作用,因為這些機器碼已經進入預讀輸入隊列內。指令快取又會讓此現象更加惡化。不過這只會在能夠自我變更的程式出現此現象。
範例
範例一
一個典型的加法指令可能會寫成像ADD A, B, C,而中央處理器(CPU)會將記憶體(Memory)內A位置與B位置的數值相加後放到C位置。在管線化處理器內,管線控制器會將這個指令分拆成一連串微指令:
LOAD A, R1
LOAD B, R2
ADD R1, R2, R3
STORE R3, C
LOAD next instruction
R1, R2和R3是CPU內的暫存器(register是CPU裡面能夠快速存取的暫存記憶體)。主存儲器內標註為A位置和B位置之存儲單元中的數值被載入(或稱複製)到暫存器R1和R2中,然後送到加法器中相加,結果輸出到暫存器R3中,R3中的數值再被存儲到主存儲器內標註為C位置的存儲單元。
而且在非管線化的例子,開始驅動加法動作到完成的時間是不變的。
在這個範例中的管線分為3層:載入,執行,存儲。每一步被稱為管線層(或稱管線階段,pipeline stages)。
在非管線化處理器中,同一時間只允許一個層運作,所以必須等待指令執行完畢才能開始執行下一條指令。在管線化處理器中,所有的層能在同一時間處理不同的指令。當一條指令在執行層,另外一條指令在解碼層,第三條指令在讀取層。
管線沒有減少執行指令所花費的時間;它增加了在同一時間被處理的指令數量,並且減少了完成指令之間的延遲。隨着處理器中管線層的數量增加,能在同一時間被處理的指令數量也相應增加,也減少了指令等待處理所產生的延遲。現在生產的微處理器至少有2層管線。[來源請求](Atmel AVR與PIC微控制器都有2層管線)Intel Pentium 4處理器有20層管線。
範例二
以下表格具體列出3層管線理論:
| 管線層(Stage) | 說明(Description) |
|---|---|
| 讀取(Load) | 從主存儲器中讀取指令 |
| 執行(Execute) | 執行指令 |
| 存儲(Store) | 將執行結果存儲到主存儲器和/或者暫存器 |
以組合語言表示將會被執行的指令列表:
LOAD #40, A ;讀取40載入A內
MOVE A, B ;將A內的數據複製到B內
ADD #20, B ;將B內的數據與20相加
STORE B, 0x300 ;將B內的數據儲存到地址為0x300的存儲器單元
代碼的執行循序如下:
| 讀取 | 執行 | 儲存 |
|---|---|---|
| LOAD |
從主存儲器中讀取LOAD指令。
| 讀取 | 執行 | 儲存 |
|---|---|---|
| MOVE | LOAD |
LOAD指令被執行,同時從主存儲器中讀取MOVE指令。
| 讀取 | 執行 | 儲存 |
|---|---|---|
| ADD | MOVE | LOAD |
LOAD指令在存儲層(Store stage),LOAD指令的執行結果#40(the number 40)將被存儲到暫存器A。同時,MOVE指令被執行。MOVE指令必須等待LOAD指令執行完畢才能將暫存器A中的內容移動到暫存器B中。
| 讀取 | 執行 | 儲存 |
|---|---|---|
| STORE | ADD | MOVE |
STORE指令被載入,同時MOVE指令執行完畢,並且ADD指令被執行。
注意! 有時候,一個指令會依賴於其他指令的執行結構(例如以上的MOVE指令)。當一個指令因為操作數而需引用一個特定的位置,讀取(作為輸入)或者寫入(作為輸入),執行那些指令的循序不同於程序原本的執行循序能導致冒險(hazards)。現時有機種技術用於預防危害,或者繞過(working around)它們。
參見
- 等待狀態
- 傳統的RISC管線
- 管線
- 並行運算
- Pentium家族的分支預測
外部連結
- 來自ArsTechnica的管線化相關文章
| ||||||||||||||||||||||||||||||||||||||||||||||||||||||


